


25.000 citazioni valgono qualcosa? La fine di SMOTE
E cosa possiamo imparare da casi come questo

Original in Italian; automatic translation into English available here.
Intro
Il mondo dell’AI e del Machine Learning non è tanto diverso da qualsiasi settore fortemente specialistico.
Dall’esterno si può pensare che ci sia una sorta di evoluzione collettiva, di miglioramento globale delle tecniche e delle metodologie, che sta portando a risolvere sempre nuovi problemi con l’AI.
Chi però vede qualcosa anche del dietro le quinte, sa bene che ci sono correnti di pensiero, opinioni forti e interessi contrastanti che animano sia il mondo della ricerca e dell’accademia, sia quello delle grandi enterprise.

Penso che alcune discussioni recenti su SMOTE (un algoritmo di cui non andrò a discutere gli aspetti più tecnici) possano essere interessanti per tante persone che stanno cercando di capire qualcosa in più di questo mondo… ma anche per tanti che neofiti non sono!
SMOTE: che cos’è, ad alto livello
Tra i problemi più complessi nel mondo del Machine Learning (ML) rientrano sicuramente i cosiddetti problemi sbilanciati.
Si tratta della modellazione e previsione di fenomeni rari, che accadono tipicamente in meno dell’1% dei casi in analisi. Pensiamo alle transazioni fraudolente nel mondo dei pagamenti o dei mercati finanziari, oppure alla diagnosi di malattie rare, o ancora al riconoscimento di eventi non comuni nei video delle telecamere di sicurezza: non è facile istruire un modello di ML, perché tipicamente nei dataset di partenza questi fenomeni sono sovrastati, in numero, dai casi opposti.
All’inizio degli anni 2000, in aggiunta agli approcci più tradizionali, è entrato in auge SMOTE (Synthetic Minority Oversampling TEchnique), un algoritmo di sovracampionamento (oversampling) per generare una quantità aggiuntiva di casi rari, fittizi ma verosimili, utilissimi per addestrare modelli predittivi efficaci.
Qui potete trovare la pagina su Google Scholar, con un numero impressionante: 26.332 citazioni.
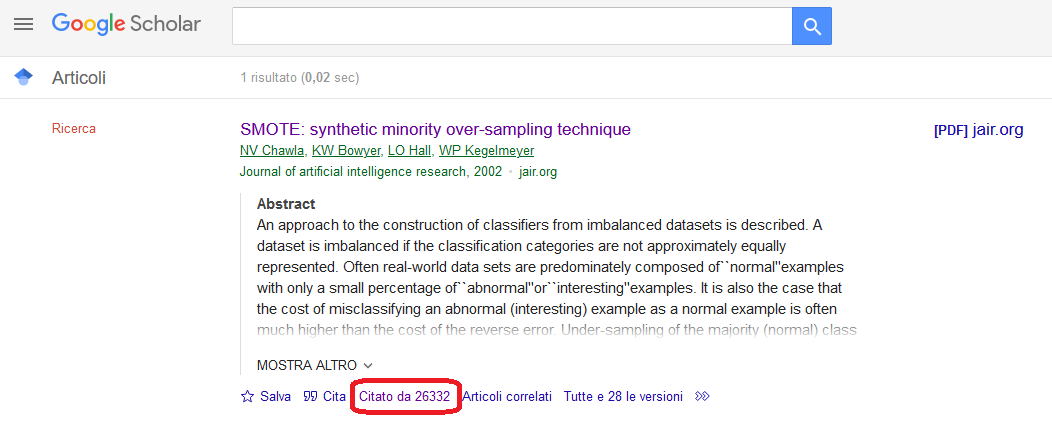
Parliamo di uno dei paper sul ML più citati di sempre. E non parliamo di citazioni di decenni fa: delle 26.000, oltre 8.000 sono del 2022 e 2023.
Fino a qui, tutto bene.
Il problema: non funziona!
C’è solo un piccolo, irrisorio problema: nella realtà, SMOTE non funziona.
Da tempo la mia esperienza diretta mi aveva convinto di questo fatto, ma quanto verificato da un singolo individuo ha un nome: aneddotica. E naturalmente non basta, neanche lontanamente!
Mi sono però imbattuto in diverse fonti, molto ricche, che sostengono la medesima teoria. Possiamo dividerle in due categorie:
Altri paper che smentiscono l’utilità di SMOTE, a cominciare da To SMOTE, or not to SMOTE?
Una raccolta di esperienze pratiche e discussioni, ben riassunte qui.
Il paper che ho riportato è corredato da codice su Github e mostra come SMOTE funzioni solo su algoritmi superati da decenni (es. alberi decisionali semplici, come CART).
Ma dal mio punto di vista, è ancora più incisivo il secondo link, che evidenzia tra le altre cose come SMOTE non sia mai stato usato su problemi reali su Kaggle. Piattaforma di competizioni di ML che ho già menzionato in un mio articolo e che ha erogato 15M€ in premi a data scientists, in centinaia di sfide su dati reali: se SMOTE fosse stato utile, sarebbe stato utilizzato almeno in qualche occasione… e invece niente.
Questa discussione su SMOTE è probabilmente contraria a quanto viene insegnato tutt’oggi in molti corsi di studio… ma come dice un noto kaggler, sarò felicissimo di ricredermi, con un controesempio alla mano su dati reali.

Riproducibilità, autoreferenzialità e inerzia
Penso siano tre gli aspetti fondamentali su cui questa vicenda può insegnare qualcosa.
Sono tuttora troppi i casi in cui paper di ricerca sono privi di dati e codice per renderli facilmente riproducibili. Lo capisco in alcuni casi: ad esempio, quando viene descritto l’utilizzo di algoritmi avanzati da parte di un’azienda, che può non essere nelle condizioni di dare full disclosure sui dati utilizzati e sul codice sorgente. Ma quando il fine di un paper è illustrare lo sviluppo di un nuovo algoritmo, dati e codice sono un must! È un bene che ci siano iniziative come Papers with Code che vanno proprio in questa direzione.
Una validazione esterna, completamente disaccoppiata rispetto a chi sviluppa il codice di un algoritmo, ha un valore impagabile. Che sia con colpa o con dolo, è molto facile che l’autore di un paper non sia ineccepibile nell’esecuzione dei benchmark sul proprio lavoro. Ed è su questo che una piattaforma come Kaggle brilla: chi fissa le regole del gioco (l’azienda che sponsorizza una competizione) è separato da chi gioca1 (i data scientists che competono). E non è un caso che librerie come Keras ed XGBoost siano state lanciate in quel contesto dai loro geniali creatori (Francois Chollet e Tianqi Chen) e da lì abbiano avuto poi un grande successo.
L’ultimo aspetto fondamentale da contrastare, in un mondo che corre, è l’inerzia: un algoritmo di preprocessing (come SMOTE) che forse aveva una ragion d’essere quando è stato disegnato, difficilmente si può sposare con algoritmi di ML sviluppati 20 anni dopo (che magari hanno approcci ad hoc per risolvere problemi come quelli dei fenomeni sbilanciati). Eppure vedo spesso, in molti progetti di ML, un curioso mix di approcci cutting-edge e vintage! Non è detto che siano sempre sbagliati, ma… attenzione.
Conclusioni
SMOTE è un ottimo esempio di un algoritmo che ha avuto un ruolo importante, nel momento in cui è stato introdotto.
Ma è giusto adottare un sano approccio critico ed evidence-driven, anche se questo vuol dire andare contro (oggi) ad un paper con 26.000 citazioni.
Nella frenesia dell’ultimo modello di AI/ML con miliardi di parametri, teniamo sempre a mente l’importanza della riproducibilità, della separazione tra chi sviluppa algoritmi e chi fa benchmark, e soprattutto del fatto che quanto è valido oggi potrebbe essere inutile o superato già domani!
Per modo di dire, visti i premi in palio!