
Benchmarking AI & ML on local CPU/GPUs: an end-to-end Python project
From idea, to demo, to a fully engineered solution. And some considerations on vibe coding.

For my regular Italian readers: it's time for an article natively in English, given the tech subject. I'll likely be back to writing in Italian soon. For an automatic translation to Italian, click here.
Intro
Running a state-of-the-art AI model on my own PC, locally, without depending on OpenAI (ChatGPT), Anthropic (Claude), Google (Gemini) and all the likes… is just fascinating to me!
Earlier this year, in January 2025, I wrote about my first experiments with a distilled version of Deepseek R1 (the Chinese reasoning model that took the AI world by storm), running on my aging desktop PC with a 7 years old GPU.
Many things happened in the meantime: I dedicated a lot of personal time to studying and especially applying AI, I published a book on the topic (together with
) that is receiving some great reviews and then, in July, I made myself a nice present.
Yep, that’s a new, shining GPU, priced just a little under 500€, traditionally used for gaming. Together with it, I carefully chose and assembled the components for a whole new PC1.
That’s where this whole project started. I couldn’t find an answer to a simple (but tricky) question.
What performance will I get with my new setup on local Artificial Intelligence workloads, whether Large Language Models or classic Predictive Machine Learning algorithms?
My curiosity / need, in details
We know that everyone is talking about AI, and most people actually use it in a way or another, relying on Big Tech solutions like ChatGPT.
In my network, just a handful of people2 actually tried AI/ML models locally, on their personal hardware (for the ML part, I started 10 years ago when competing in Kaggle… but that’s for another article).
Especially for GenAI models, the focus is usually on the capability of local models to produce reasonable answers: there’s plenty of benchmarks that all measure (in different ways) the accuracy of such models.
Here comes the tricky part: commercial solutions like ChatGPT are often able to produce 100s of tokens per second. To put it simply: their speed in answering (i.e., producing tokens) is way superior to the reading speed of a human.
On the other hand, running an AI model locally may result in just single-digit tokens per second: too slow. Sometimes even 1-2 token/s, for models that do not fit in the RAM of the GPU (or CPU).
When deciding which GPU to buy, I would have loved a public, open benchmark to navigate and find the sweet spot for price/performance ratio on this aspect. I found nothing relevant and updated. So I went ahead and bought an Nvidia 5060 Ti 16GB based mostly on the available benchmarks for gaming (plenty!), doing a bit of a leap of faith that they would be correlated to the speed of local AI workloads.
Step #1: a benchmark for real-world Python libraries
At first, I spent some time setting up my new PC and enjoyed the improvements over my old one, which were visible even without proper benchmarking.
But I wanted some actual numbers (I’m an engineer, after all). And I wanted to code (and vibe code) a bit, trying some new tools and libraries.
Spoiler alert: all the code related to this section is freely available on Github.
I started with a couple of constraints for this side project (more will come over the course of this article):
Only use free and open source libraries and real-world tools that data scientists and AI engineers actually use.
Allow for both CPU and GPU benchmarking, separately (it’s very interesting to understand why Nvidia is the largest company in the world, by capitalization… but some people actually do not have an Nvidia GPU, including myself on a spare laptop that I have lying around).
What I ended up using:
Python 3.13 with uv as package manager to integrate the various dependencies (amazing Rust-based software, really a step forward in speed and simplicity when compared to my previous favorite, Poetry).
CUDA 12.x, needed to leverage an Nvidia GPU.
Ollama, a nice framework to run local generative AI models.
XGBoost, the machine learning library that every data scientist uses (or should use) for predictive modeling on tabular data, which works on CPUs but added support for GPUs a few years ago.
Altair, a nice and lightweight plotting library for showing the results. Much prettier than Matplotlib and Seaborn, much lighter and feature-rich than Plotly.
The benchmark is pretty straightfoward, let me just outline some key elements before showing some results and the Github repository.
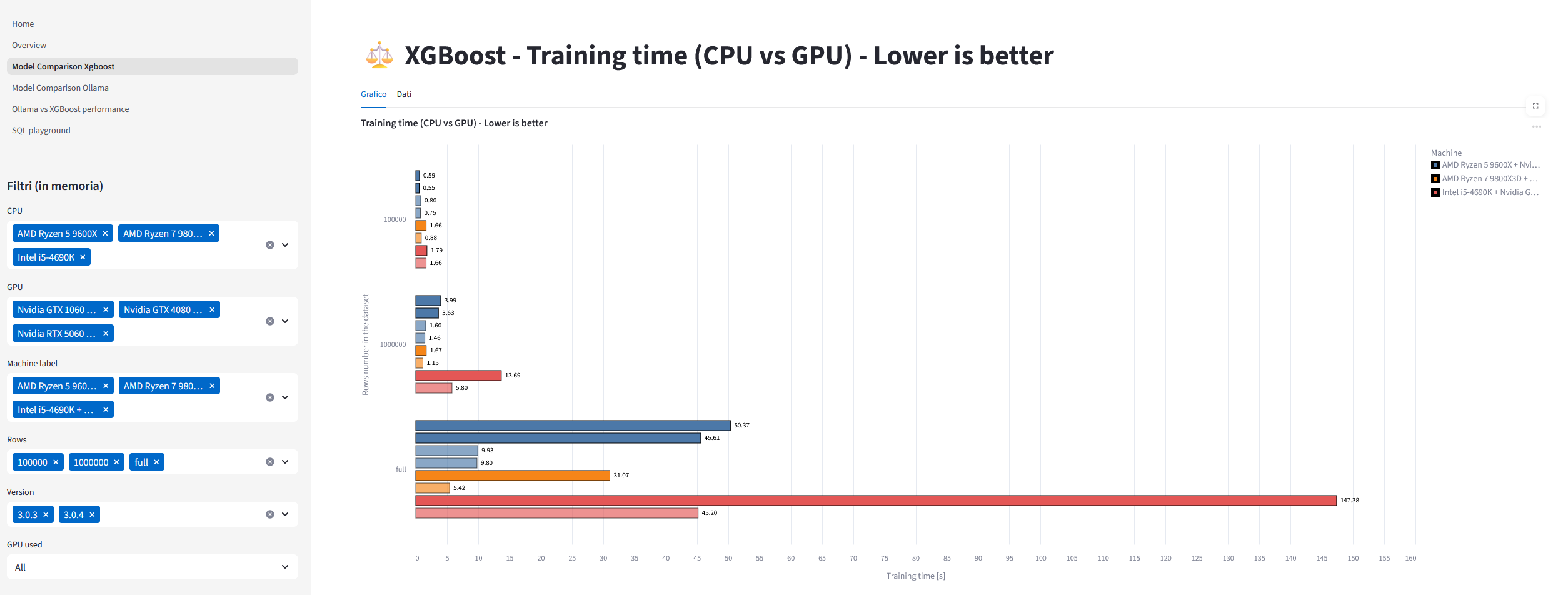
For XGBoost, the benchmark downloads the famous HIGGS dataset and allows for subsampling the rows to be used (the default uses three combinations: 100K rows, 1M or the full 11M dataset). Training time (the lower, the better) is the key metric.
For Ollama, some of the most common open source models are used, with different sizes (from 4B to 14B). Token per second at inference time (the higher, the better) is the key metric.
The benchmark is run by default 3 times for each combination and the median result is the one showed. CPU, GPU or both can be used.
All of the above can be configured via a single YAML file.
Some initial results
Below you can see some results between my old (orange) and new pc (blue), on Ollama, where solid colors are CPU benchmarks and semi-transparent are on GPUs.
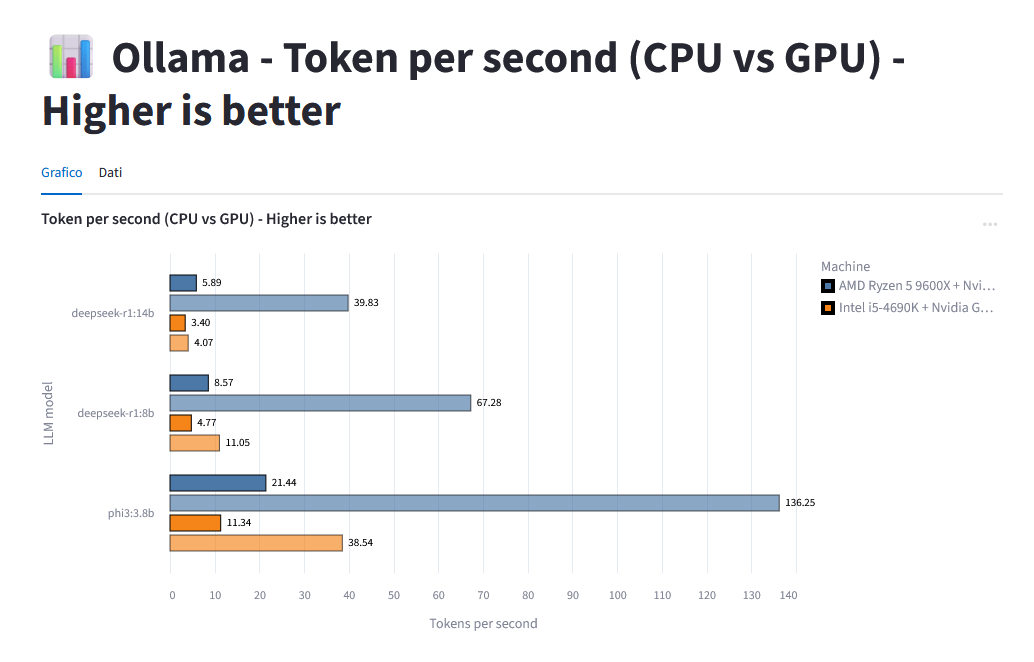
On the 14B distilled Deepseek R1 model, my new GPU produces 40 tokens/second, while my new CPU and old CPU/GPU are all below 6! This is due to the speed of the 5060 Ti and the good amount of VRAM (16GB), where all Deepseek R1 14B can fit.
On a much smaller model like Phi3 with 3.8B parameters, the new GPU gets an amazing 136 tokens/s, but also the old one (GTX 1060 with 6GB of VRAM) is capable of a decent 38 token/s.
There’s plenty of considerations to be done. A current generation GPU is roughly 7-8 times faster than a current CPU3. And the improvement over the years is also favourable to the GPU: my current one is 4 to 10 times faster than a 7 years old GPU, while my new CPU is roughly “just” 2 times faster than the old one.
To run your benchmark, just head to Github and follow the README, it’s actually quite easy: https://github.com/albedan/ai-ml-gpu-bench
At the end of the benchmark, the results are shown in a Jupyter notebook, so you can get some insights at a glance, with your results compared to the reference ones.
Step #2: from personal demo to a complete architecture
I was satisfied with my little side project and I also collected some other results and suggestions by talking to some friends4.
But as they say, success breeds ambition. And this demo, as it was, couldn’t scale. A few questions came to my mind:
How can I enable other people to share their results? How can I create a proper database for the possibly tens or hundreds of benchmarks? How can I make it easy to navigate the results?
Let’s break it down.
Sharing results
I was looking for free, unauthenticated cloud storage. Free was my original constraint, but the real reason was that opening to the public a service paid by me (e.g., an S3 bucket) requires a lot of attention to security stuff. Unauthenticated as obviously I didn’t want to require any authentication from the benchmark users.
After a few experiments, I settled with Filebin.
What happens in the current release of the benchmark is that results are saved as CSVs, encrypted with a public 4096 bit RSA key of mine (i.e., I have the private counterpart) and uploaded to a bin in Filebin (opt-out option available for the selfish ones who really don’t want to contribute 😞).
Collecting new results
At first, I thought about manually checking the bin… not the best option. So I decided to develop a Telegram bot to notify me of new files. Pretty easy and quite fun!
The bot is actually responsible for writing to a given Telegram group/channel, but where does it run? Again, looking around I found the perfect solution for me: Github Actions.
It’s an amazing automation tool that lets you orchestrate, schedule, run various actions (all coded in Python, in my case). My first need was monitor Filebin daily and notify of new files… but I could do much more!
Growing the results database
I had the notifications up and running, but why not creating a proper database for storing the results?
Motherduck has been my choice, for simple reasons: every nerd in 2025 loves DuckDB and Motherduck provides a good free tier, a nice interface, APIs for integration.
My Github Actions workflow, originally meant for notifications only, grew accordingly: I added the download of the files from Filebin, decryption with my private key (stored obviously as secret), schema validation, insert in a staging area in Motherduck.
This was probably the hardest part for me: I’m not sure if that was due to the innate complexity of this (including the not always clear Filebin’s API and the tricky decryption of files) or my limited experience on such topics.
The one and only part that I decided to keep manual is the promotion from the staging area to the reference one in Motherduck, not for technical reasons, but just to be in control of what becomes an official result.
Making results easy to navigate
All of the above is a sort of integration layer - and is currently in a dedicated, private repository.
I was just missing a final step, quite easy but very visible: building a dashboard to navigate the results… and support decision making when buying a GPU to play around with local AI and ML!
Streamlit was my library/tool of choice: 100% Python based, widespread, easy to use for someone very far from UX/UI like myself. And obviously integrated with Streamlit Community Cloud, the perfect solution for sharing the dashboard (again, for free) with anyone interested in this project.
It didn’t take long for me to design a good enough dashboard, with a few pretty visualizations and also a nifty SQL playground.
You can find it here5: https://ai-ml-gpu-bench.streamlit.app
Wrapping up the architecture and some thoughts
Here is the architectural diagram I made with Mermaid.
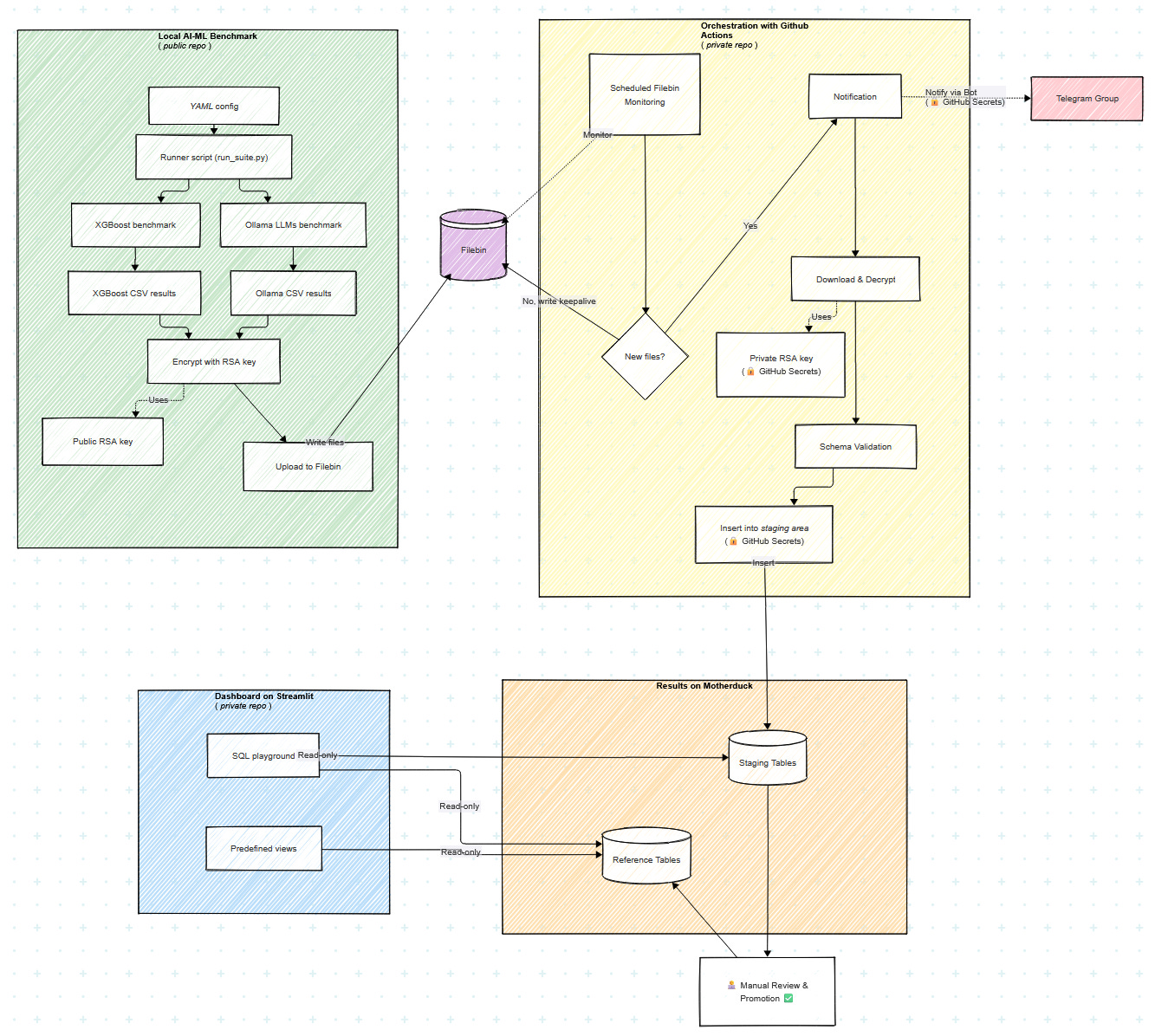
Hopefully you got they key steps of the project:
I started by simply timing the training and/or inference with local AI/ML models and providing an exploratory Jupyter notebook.
I added the encrypted upload of results to a dedicated cloud storage.
I engineered the download, decryption, validation, integration of results to a cloud database, all in a serverless way.
I enabled the possibility to explore visually the results.
I had a lot of fun. I’m a computer engineer by education and my role has been very similar to Pat Kua’s lead of leads for the last few years6. That is, coding is not really part of my daily job.
This project gave me the chance to take some rust off (no pun intended)!
From idea, to proof of concept for my own amusement, to a solution that anyone can run and that allows sharing and navigation of results. I feel the kind of satisfaction an artisan feels when crafting something by hand, with my raw materials being libraries, tools and code.
What’s been mind blowing for me is the sheer number of challenges I faced over a few nights of work, and the amazing technologies that have made all of this possible. And I’m 100% sure that I learned more in this project than with tens (or even hundreds) of hours of structured education.

The manager’s corner: Q&As
I’ve been working in corporate environment for the last 18 years, most of them in various managerial roles. And as a colleague of mine told me, “you don’t really expect a manager to do such things”!
Obviously such project has been helped tremendously by the use GenAI tools for coding.
I think it’s a priviledge to both be hands-on and be a manager, so let me answer some common questions that are very frequent among CxO these days.
What GenAI tools did you use?
I tried mainly 3 solutions:
A native AI IDE (Windsurf with its own model): unimpressed.
A standard IDE (VScode) plus local AI models for coding (Devstral 24B with Continue): unimpressed.
A standard IDE (VScode) and ChatGPT on a side: while definitely unsophisticated, it worked great for me. Chatting with o3 and later GPT-5 gave me a lot of ideas (and some code), using o3-pro and GPT-5 Pro helped me overcome the toughest obstacles.
If I had to code all day, I would spend some time in finding a more effective approach.
What was the speed up by using GenAI coding assistance?
This is an ill-posed question: I would have stalled without GenAI support. My personal time is limited (as is everyone else’s) and I’m 100% sure I’d have thrown in the towel. Coding, automation, integration, architectural choices, existing solutions to adopt or adapt: I faced a lot of topics and challenges that are very far from my expertise.
To some extent, this equals to a “plus infinite” speed up. 😝
On a serious note, real coding should not be seen as a blue collar job, where better tools allow for faster production. This is well known in tech, even if those who sell AI solutions for coding or consultancy will state otherwise… for obvious interests!
How would you rate your (GenAI-assisted) code?
I’d give 6 out of 10 (maybe I’m generous). The final code is the result of suggestions from AI, multiple manual reworks, other suggestions, and so on. I’m not a coder full time, but I can recognize beautiful code… at the moment, this is not.
But it works, and it’s fine for a fun side project. I’ll refactor something, maybe, in the future7.
On the other hand, it’s not fine for corporations and all the companies who more and more rely on GenAI assisted code. I think it’s very likely that the technical debt will grow exponentially over the next few years, increasing the gap between real tech companies (who care about code quality, standards and coherent IT and software architectures) and all the others.
What’s the value you’ve seen in using GenAI for coding?
The value is not an X% speedup in coding, it’s joy. Realizing that we all have a smart assistant that can provide us ideas and support means that committed and skilled individuals can now face greater challenges.
And feel the satisfaction of transforming ideas into results.
Is it over for software engineers?
For mediocre developers, yes, it’s over (or will be very soon).
But looking back at this project, it’s been key to have a good understanding of a broad set of technical topics: without it, I wouldn’t have been able to ask the right questions, evaluate the answers, ditch several wrong (or weird) suggestions that I received.
A solid STEM (and in particular computer science) background is in my opinion more and more relevant to leverage such tools. If you don’t know what to ask, you’ll never receive a smart answer, let alone being able to evaluate it.
Conclusions
It’s been quite a journey!
Starting from the benchmark itself, we’ve seen that consumer GPUs can actually run local AI/ML models with very good throughput and speed, but also CPUs allow at least to experiment a little bit. The performance increase over the last few years has been impressive. And if you navigate the existing results, you’ll see also what an high-end gaming GPU (not mine 😢) is able to achieve.
Collecting more results is crucial and I think it may be useful to a lot of people (or maybe small companies) looking for indipendence from Big Tech providers of AI services.
So… give it a try and spread the word (and the links):
Navigate the results dashboard: https://ai-ml-gpu-bench.streamlit.app
Run the benchmark and contribute: https://github.com/albedan/ai-ml-gpu-bench
And get in touch for any questions!
I talked a lot about the technologies that I used and my vibe coding experience: I will not repeat myself.
Just a suggestion: take an idea, a curiosity of yours, and force yourself to spend some time actually experimenting. You’ll learn so much by bridging the gap between theory and practice!
For those looking for more information, besides the GPU:
CPU: AMD Ryzen 5 9600X (AM5, Zen 5 architecture)
Motherboard: ASUS TUF Gaming B850-Plus WiFi
RAM: 64GB kit (2x 32GB) Crucial Pro DDR5-5600 (46-45-45) @ DDR5-6000 (40-42-42)
SSD: Western Digital 2TB SN7100
PSU: Corsair RM650e
Case: Corsair Frame 4000D (plus some fans)
HSF: Thermalright Phantom Spirit 120
Roughly 900€ + GPU, for a grand total of 1400€.
Despite the percentage of nerds and geeks being way over represented!
I’d say that both the Ryzen 5 9600X and the Nvidia 5060 Ti 16GB belong to the same “upper mainstream” segment in their respective category (i.e., CPU and GPU).
Thank you Claudio, Guglielmo, Manuel and Marco!
If not visited for some time (I guess around 24 hours) it goes in sleep mode, but can be awakened with a click and waiting for 10-15 seconds.
“5 Engineering Manager Archetypes” is a must read for anyone in tech leadership roles.
This usually means “never”, unless the project gets some traction!