


Come si misura l'efficacia dell'Artificial Intelligence?
Strategie adottate per essere oggettivi e superare l'autoreferenzialità... la base per l'innovazione, quella vera!

Original in Italian; automatic translation into English available here.
Intro
Se dico ILSVRC, chi sa di cosa sto parlando? Penso pochissimi.
E se spiego l’acronimo, ImageNet Large Scale Visual Recognition Challenge? Magari a qualcuno si è accesa una lampadina!

Beh, per chi si è avvicinato all’AI solo negli ultimi 5-6 anni, e ancor più per chi ha scoperto questo mondo con ChatGPT, questa è una storia da conoscere.
C’è stato un lontano passato, tra il 2010 e il 2017, in cui ci si chiedeva se fosse possibile per un algoritmo (oggi diremmo un’AI) superare l’essere umano medio in 3 tipologie di compiti: individuare un oggetto (o più) in un’immagine, localizzarlo all’interno della stessa ed eseguire lo stesso task su di un video.
Precisamente, nel 2010 se lo chiedeva Fei-Fei Li, uno dei grandi nomi dell’AI moderna che negli anni è stata Chief Scientist of AI/ML in Google, docente a Stanford e referente per il dottorato di persone del calibro di Andrej Karpathy. Una giovane donna, ai tempi non ancora 35enne, che ha davvero plasmato gli ultimi 15 anni nel mondo dell’AI.
La sua idea geniale è stata quella di standardizzare le valutazioni di questi tre compiti, andando da un lato a creare dei dataset per valutarli, dall’altro a definire le metriche in modo da avere misure di performance oggettive e indiscutibili.
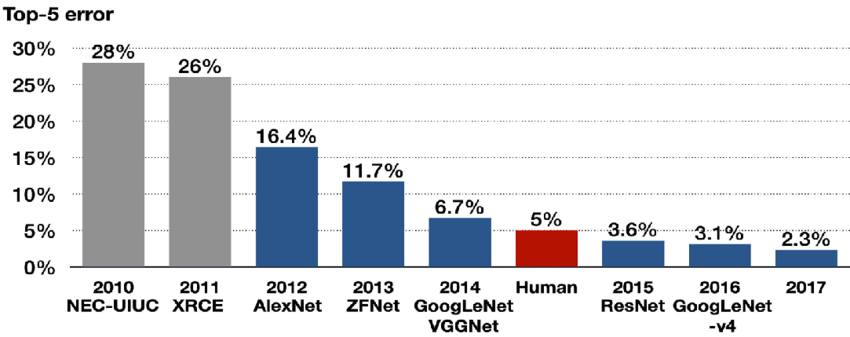
Il resto è storia. A fronte dell’umano medio che commette un 5% di errori:
il miglior algoritmo del 2010 faceva ben il 28% di errore
nel 2015 c’è stato il sorpasso degli algoritmi
nel 2017 la differenza si è fatta sempre più marcata e ILSVRC è stato prima spostato su Kaggle e poi sostanzialmente smantellato
La storia è interessante in sé, ma è solo il primo degli esempi che mi è venuto in mente per un concetto più ampio.
Misurazioni oggettive vs. autoreferenzialità
Molti si chiedono cosa abbia portato all’accelerazione dell’Intelligenza Artificiale negli ultimi anni.
La disponibilità di GPU e potenza di calcolo? Vero. Gli investimenti enormi fatti da più parti? Vero. La capacità di attrarre le migliori menti per lavorare su questi temi (e non su altro)? Verissimo anche questo.
Ma c’è anche quello che gli americani chiamerebbero un unsung hero, un eroe dimenticato: il sostanziale abbandono dell’autoreferenzialità e delle cerchie ristrette, a favore di trasparenza, accessibilità e oggettività nel misurare gli avanzamenti tecnologici.
Ritengo che il mondo dell’informatica, della matematica applicata, dei dati - ossia tutto quello che è alla base dell’Intelligenza Artificiale - sia da questo punto di vista un esempio virtuoso che potrebbe/dovrebbe essere d’ispirazione anche per altri settori.

Se ci guardiamo attorno, non è poi così frequente questa propensione a misurare oggettivamente le idee e gli approcci che funzionano. Nelle grandi aziende, ad esempio, qualcuno sostiene che abbia sempre la meglio il cosiddetto HiPPO: non parlo del corpulento erbivoro, ma della Highest Paid Person Opinion. Nell’accademia spesso si guadagna credito grazie a metriche come il numero di pubblicazioni e citazioni, quantitative ma non certo infallibili… e poi non c’è da stupirsi se vengono ancora insegnati algoritmi descritti in paper con 25.000 citazioni, anche se in realtà sono stati già smentiti da tempo.
Ecco, negli ultimi 10-15 anni il mondo dell’innovazione e dell’AI ha preso una direzione diversa, almeno nella maggior parte dei casi: quella di standardizzare la definizione di successo e di efficacia degli algoritmi.
Se pensate che sia semplice… no, non è così. Il mondo dei benchmark e delle misure sull’efficacia dell’AI è in continuo sviluppo e prevede tanti approcci differenti. Penso sia utile conoscerli, anche perché alcune di queste idee possono essere mutuate anche in altre realtà, come aziende grandi e piccole.
Partiamo dalle basi: facilitare l’accessibilità
Le barriere all’ingresso del mondo dell’AI sono state abbattute con una parola: accessibilità.
Se devo scegliere tra 3 sole fonti che stanno facendo accelerare il mondo dell’AI, direi:
HuggingFace, la piattaforma collaborativa che è diventata il punto di riferimento per pubblicare e rendere fruibili i modelli di AI open source
Papers with code, ottimo riferimento per avere sotto mano non solo i paper (testuali), ma anche i dati e il codice usati per ottenere i risultati presentati
Github, che non è specifico del mondo AI, ma è comunque la piattaforma di riferimento per tutto ciò che è codice open
Questi sono però strati abilitanti, non sono benchmark o modalità di valutazione di modelli.
Primo approccio: creare dati e test standard
Seguendo l’idea di Fei-Fei Li, negli ultimi anni sono nati una serie di dataset standard pensati per misurare l’efficacia di algoritmi di AI su una varietà di compiti.
Come rappresentato benissimo sul sito di Confident AI, l’idea è molto semplice:
Ogni benchmark contiene una serie di domande a risposta multipla da proporre ad un algoritmo di AI
Le risposte fornite vengono valutate rispetto alla ground truth
Si può costruire in questo modo una classifica oggettiva

Per fare un paio di esempi:
MMLU (Massive Multitask Language Understanding) è un benchmark di comprensione del linguaggio che spazia dalle materie umanistiche a quelle scientifiche

Hellaswag è un benchmark sul buon senso… ossia su domande scontate (o quasi) per un essere umano, ma molto meno per una macchina


E così tanti altri.
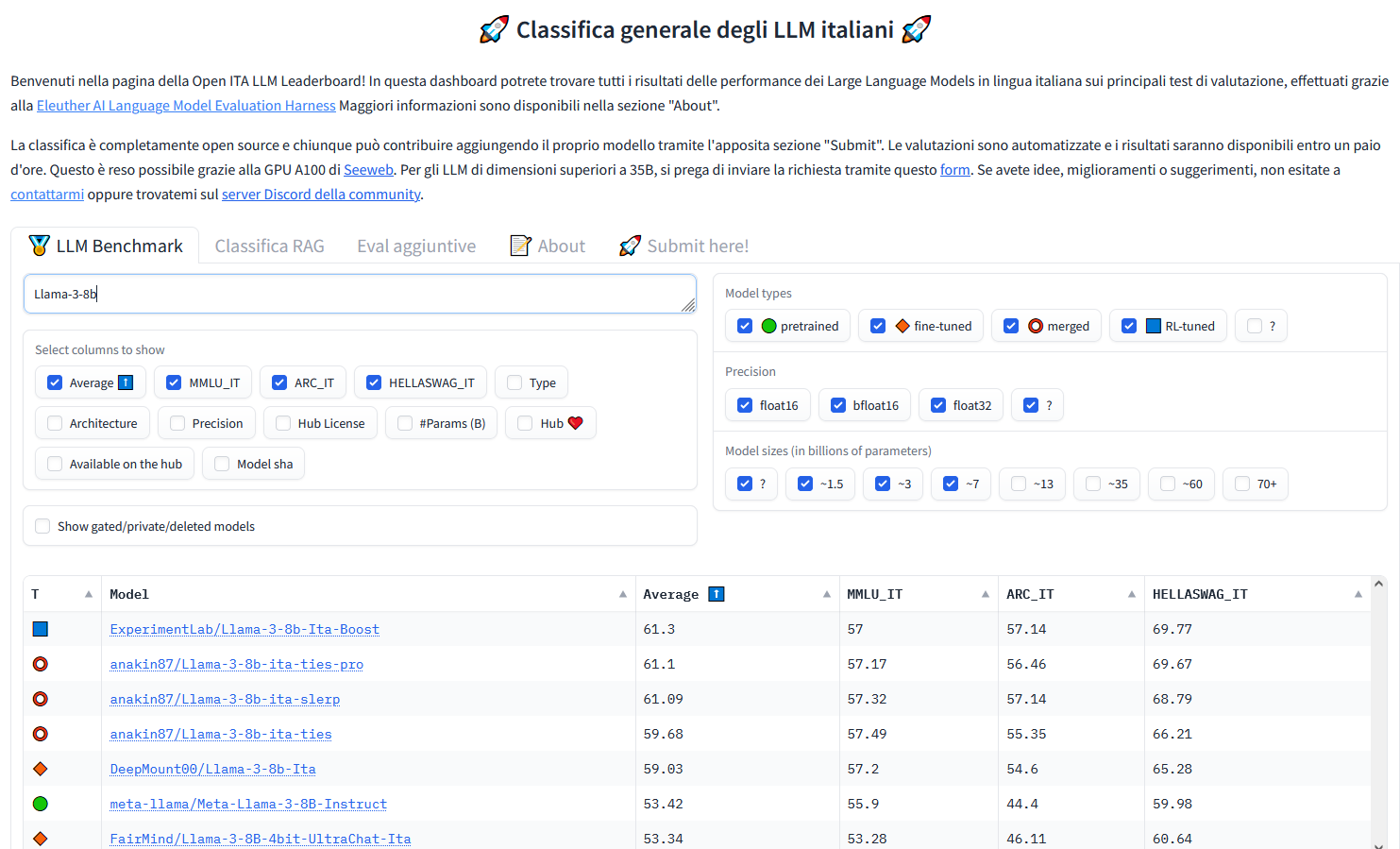
In questa maniera è possibile fare delle classifiche oggettive molto interessanti! Classifiche che tipicamente includono i cosiddetti base models, ma magari anche modelli con fine tuning su specifici domini.
Da notare che esistono classifiche anche molto specifiche, come quella sulle performance dei modelli in lingua italiana.
Che differenze ci sono tra un LLM grande o piccolo, tra un modello base ed uno con fine tuning? Non a livello qualitativo, ma in termini percentuali sui vari benchmark? Le risposte sono tutte lì dentro.
Questo approccio è molto simile a quello delle competizioni su Kaggle, su cui sono stato parecchio attivo e di cui ho già parlato, con qualche differenza:
le classifiche degli LLM si basano su benchmark pubblici, mentre le competizioni Kaggle hanno una componente privata (per permettere di assegnare premi senza che nessuno bari)
Kaggle prevede una durata prefissata (tipicamente 90 giorni) per ogni competizione, dopodiché la gara viene archiviata e rimane tipicamente solo come informazione storica
Secondo approccio: tra un trial clinico e un campionato di scacchi…
L’altro approccio principale nel misurare un LLM ricorda tanto i trial clinici in doppio cieco.
L’idea è semplice ma geniale: viene chiesto ad un essere umano di proporre una domanda / un argomento e poi valutare le risposte fornite da due LLM… ma senza sapere quali LLM sono in gioco!

In particolare, si può assegnare un pareggio, oppure dare la preferenza ad un LLM rispetto all’altro.
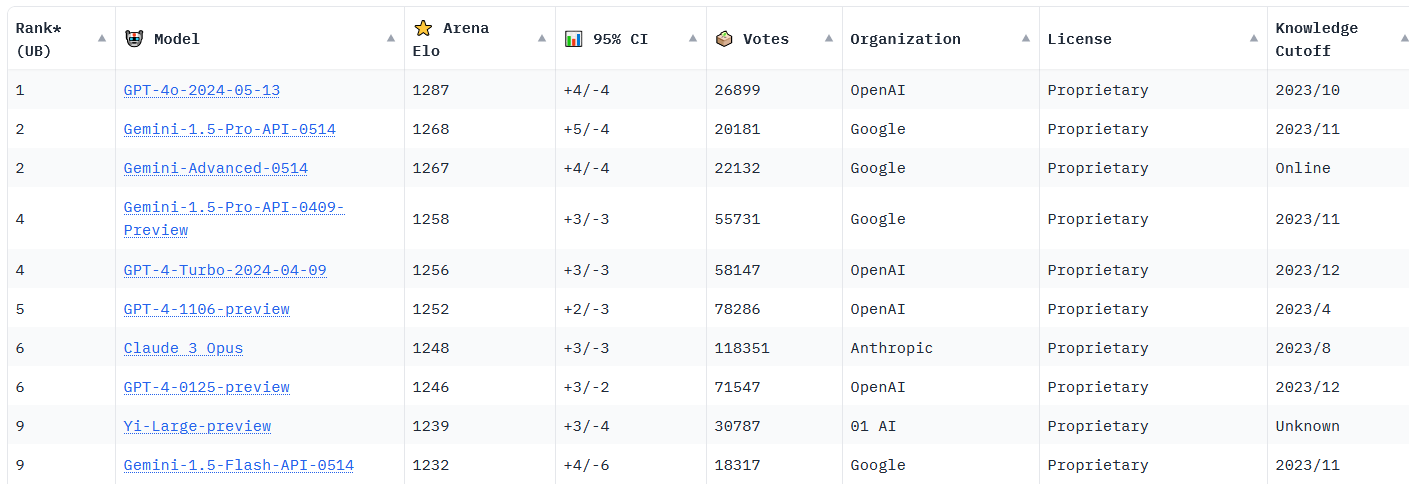
Possiamo dire che così gli LLM si sfidano, come se fosse una partita a scacchi… e quindi perché non fare una classifica a punti Elo, dove al posto di Magnus Carlsen, Hikaru Nakamura e altri scacchisti ci sono GPT-4o, Gemini, Claude e affini?
Conclusioni
Mi rendo conto di avere un debole per soluzioni smart ed eleganti verso problemi estremamente complessi come può essere la valutazione degli LLM, ossia di algoritmi di Intelligenza Artificiale.
E qui abbiamo visto due esempi fantastici: da un lato lo sforzo di standardizzazione dei test, sulle orme di ILSVRC, dall’altro un approccio furbo per far gareggiare gli LLM come in un test clinico… oppure in un blind tasting tra due eccellenti vini!
Va detto che la perfezione non esiste: c’è sempre il rischio di overfittare il benchmark, ossia di allenarsi solo su quello. Un po’ come quello studente universitario che impara a passare l’esame con 30L, senza avere realmente capito nulla della materia in sé.
Ma pensiamo un attimo alle alternative: ci sono tanti settori molto chiusi, autoreferenziali, dove tutto si poggia su titoli o sull’appartenenza alla giusta cricca, piuttosto che su oggettive dimostrazioni di competenza.
Il mondo dell’AI e della tecnologia si è prestato particolarmente bene a ribaltare vecchi paradgimi, e non sarà facile adottare questi approcci in realtà molto diverse… ma anche realizzare (o solo concepire) l’AI che vediamo oggi era impensabile fino a qualche anno fa, quindi ci sono speranze!