


GenAI: 8 fatti (e non opinioni) per manager e decision makers che non vivono sulle nuvole
Guida pratica per non confondere realtà e fantasia

Original in Italian; automatic translation into English available here.
Intro
C'è un livello di "wannamarchismo" sugli LLM che supera tutte le nefandezze che abbiamo sentito raccontare negli ultimi 10 anni, che già sono tante. Purtroppo però mi fa venire la depressione, questo paese è spacciato.
Così mi ha scritto qualche settimana fa il founder e CEO di una startup tech italiana di successo. Dove per inciso la mia definizione di successo non è filosofica: prima un prodotto tech di livello, poi il fatturato, quindi gli utili, ed infine una bella exit.
Sotto sotto penso che abbia abbastanza ragione: al di fuori delle cerchie più nerd1, le discussioni italiane sulla Generative AI sono spesso surreali, che si tratti di comunicazioni sui mass media o di quanto avviene in contesti più ristretti.

Io però ho ancora un barlume di speranza, e sono convinto che a fronte di un po' di Wanne Marchi e Maghi do Nascimento (boriosi, incompetenti e rumorosi), ci sia una maggioranza silenziosa di persone curiose, capaci nel proprio settore, appassionate e desiderose di capire qualcosa di più del mondo dell'Intelligenza Artificiale, generativa e non.
E quindi, nel mio donchisciottesco tentativo di contrastare un andazzo che vedo da più parti, ho deciso di raccogliere un po' di fatti oggettivi e verificabili sulla Generative AI. Senza conflitti di interessi più o meno grandi, senza secondi fini, senza motivazioni particolari se non quella di fare un po' di education, da persona molto pragmatica che si occupa di questi temi da parecchio.
Bisogna capire di più, per temere di meno (e non farsi fregare / non restare delusi)
Come da mia libera integrazione della famosa frase di Marie Curie, quando si parla di scienza (e anche di AI) è fondamentale capire e non fermarsi agli slogan. Per superare alcuni legittimi timori, sicuramente, ma anche per non correre il rischio di tutte le grandi rivoluzioni tecnologiche:
Credere al sogno di turno
Rendersi conto della fregatura
Finire per “buttare via il bambino con l’acqua sporca” e perdersi tante opportunità reali
In questo articolo, ho voluto dare un taglio che guarda soprattutto ai manager che sul fronte della Generative AI non vogliono farsi abbindolare dal vendor, consulente, o fantomatico esperto di turno... ma anche ai tecnici, che spesso vivono nella propria bolla di competenza e faticano a capire le impressioni e il percepito che ci sono nel mondo esterno.
Mi sono ripromesso di riportare solamente fatti, che - news del giorno - anche nel mondo della GenAI non coincidono né con le opinioni, né con i sogni.
Generative AI vs. Machine Learning ed AI “tradizionale”
1. L’AI Generativa ha superato l’AI tradizionale, rendendo obsoleti relativi ruoli e buone pratiche?
Nel 2023, sono stati messi in palio oltre 7,8 milioni di dollari in competizioni pubbliche per realizzare algoritmi di AI/ML in grado di risolvere problemi reali, tipicamente sponsorizzate da aziende attraverso piattaforme dedicate (in cui Kaggle naturalmente la fa da padrona).
Considerando che ChatGPT è stato lanciato a fine 2022, è legittimo chiedersi quante di queste competizioni siano state vinte grazie alla GenAI.

Il report The State of Competitive Machine Learning 2023 è una miniera. Questo è il riscontro:
Given their rise in general usage, it’s no surprise that large language models (LLMs) are proving useful in competitive ML too. However, they are far from ubiquitous among winning approaches.
From our findings, most winners either explicitly said they didn’t use LLMs in any way, or didn’t mention any use of LLMs.
I casi di utilizzo sono in grandissima parte assistenza al coding (stile Github Copilot e affini): parliamo di un piccolo supporto GenAI-based, ma al momento è evidente che una GenAI non è in grado di risolvere in autonomia problemi complessi e ottenere risultati di eccellenza in contesti competitivi e specifici.
2. Nel mondo della GenAI, la partita si gioca sulla potenza di calcolo e le GPU a disposizione?
La potenza di calcolo ricopre un ruolo molto importante nell’addestramento di modelli di Generative AI, sicuramente più che in quella tradizionale: ho già parlato dei due cluster di Meta, ciascuno di un valore stimato di 1 miliardo di dollari.
È sicuramente una condizione necessaria, ma non sufficiente.
Leggendo un po’ di articoli, come il sempre ottimo recap di Llama-3, quello che emerge è che ci sono (almeno) altri due grossi aspetti, oltre alla forza bruta dei cluster di GPU.
Il primo è rappresentato dai dati su cui gli LLM sono addestrati: lo sforzo in questo senso è enorme. Come dicono sempre da Meta:
To train the best language model, the curation of a large, high-quality training dataset is paramount.
In line with our design principles, we invested heavily in pretraining data.
Il secondo è l’architettura del modello. Prendiamo Gemma-2-9B, un modello relativamente piccolo lanciato da Google un mesetto fa, e confrontiamolo con GPT 3.5 Turbo di OpenAI, modello molto più grande (e quindi più costoso da addestrare), che era lo stato dell’arte un anno e mezzo fa.
Come si vede sotto, Gemma-2-9B supera GPT 3.5 Turbo sia come performance che come velocità, e questo si deve a nuove ed efficaci idee modellistiche.

3. La GenAI richiede investimenti immani rispetto a quella tradizionale, o viceversa è gratis, come ChatGPT?
La situazione è abbastanza delineata: attività diverse hanno costi enormemente diversi. Partiamo dai costi diretti:
Addestramento di un modello LLM foundational (da zero): se si vuole sviluppare qualcosa che non sia un giocattolo, servono da svariati milioni fino ad un miliardo o più di dollari - l’articolo di Meta citato in precedenza è un buon punto di partenza per approfondire, ed oltre al costo delle GPU c’è naturalmente anche il consumo energetico2;
Fine tuning di un modello già addestrato: che sia per adattarsi ad una specifica lingua, oppure per migliorare il modello per uno specifico settore/dominio (legale, medico, etc.), qui parliamo di centinaia o migliaia di dollari - una cifra abbordabilissima. Mi viene in mente il progetto Allamo di tuning di Llama-3 su lingua polacca (44 giorni su una singola GPU retail acquistabile nei negozi per 2.000€ circa), oppure altre stime nell’ordine delle centinaia di dollari.

Un esempio di costo stimato di fine tuning Fruizione di API per l’inferenza / utilizzo degli LLM: qui i prezzi sono di alcuni dollari per milione di token processati in ingresso o uscita, come nel caso di GPT-4o

Fruizione dell’inferenza con interfacciamento manuale: tanti fornitori di LLM, da OpenAI ad Anthropic, permettono di utilizzare gratuitamente3 i propri servizi, quando ad interfacciarsi è una persona in carne ed ossa sul proprio sito web


Naturalmente, l’elefante nella stanza sono le altre voci di costo oltre al mero hardware ed elettricità. Ad eccezione dell’ultimo punto, fare addestramento / fine tuning / interfacciamento con gli LLM ha per un esempio un costo rilevante legato ai professionisti che sono richiesti. Tema troppo grande per essere affrontato qui!
Il futuro degli LLM
4. Tra N anni, rimarranno solo OpenAI, Anthropic e altri grandi player con i loro LLM? O a dominare saranno gli Small Language Models?
Non ci sono evidenze in un senso o nell’altro, solo opinioni e alcune vicende specifiche.
È un dato di fatto che poco più di un anno fa Bloomberg annunciò in pompa magna il proprio BloombergGPT, un modello addestrato sui propri dati finanziari, costato oltre 10M$ (sull’architettura di GPT-3.5, ormai superata).
Beh, oggi è agevolmente superato da GPT-4 (neanche nelle sue ultime versioni), modello general-purpose usabile via API.

D’altro canto, il fine-tuning di Small Language Models è tutt’altro che morto, e tanti sono i buoni motivi, due in primis:
la volontà di non legarsi mani e piedi ad un fornitore di LLM che potrebbe cambiare i listini molto rapidamente;
il desiderio di avere un deploy locale, ossia un server interno all’azienda per non avere costi di chiamate API e piena garanzia di riservatezza.
Alcune piattaforme dedicate (come Predibase dell’italiano Piero Molino) mostrano benchmark interessanti (ma non di terze parti):

Lo scontro LLM vs SLM è ancora in corso ed è presto per dichiarare un vincitore… e non è detto che ce ne sia uno solo per tutte le esigenze.
5. Per gestire al meglio la lingua e la cultura italiana, servono LLM nazionali?
Una narrazione molto affascinante racconta dell’esigenza di addestrare da zero dei modelli linguistici che si basino sulla nostra bellissima e unica lingua madre, col risultato di rappresentare al meglio tutte quelle sfumature che ci contraddistinguono.
Ma… è vero?
Ci sono due benchmark di livello su questo fronte. Mi focalizzerò sul test INVALSI per studenti di medie e superiori, usato da alcuni ricercatori dell’Università Milano Bicocca come strumento per confrontare i principali LLM esistenti ad oggi.
Le domande sono tutte nativamente in italiano e non proprio scontate (se pensiamo che a rispondere è… un’intelligenza artificiale, ossia un algoritmo), come potete vedere sotto

La classifica è disponibile pubblicamente. Su una scala da 0 a 100:
92,2: il miglior modello, Claude 3.5 Sonnet di Anthropic;
79,5: il miglior modello open source, Qwen2-72B di Alibaba (sì, il miglior modello open sull’italiano è made in China, addestrato su tante lingue tra cui l’italiano, che non è certo una delle più diffuse al mondo). 72B è una dimensione media;
73,8: il miglior modello open source di piccole dimensioni, Gemma-2-9B di Google;
59,8: il punteggio di uno studente medio riportato nel paper;
25,7: il punteggio del miglior LLM italiano nativo (Italia-9B di iGenius), in 27esima posizione su 28;
20,5: il punteggio che si otterrebbe fornendo risposte a caso4.
L’altro benchmark sulla lingua italiana è la Open Ita LLM Leaderboard, che include solo i modelli open (quindi non presenta i top performer), i cui risultati sono del tutto comparabili.
Questo è giusto un reality check ed è lo stato al momento della stesura di questo articolo5.
Generative AI, lavoro e produttività
6. Si comincia a vedere l’effetto della Generative AI nel Tech, con un aumento dei layoff?

Questa è la situazione reale dei layoff (licenziamenti massivi) nel mondo tech, riportata dal sempre ottimo layoffs.fyi.
Si vedono diverse fasi:
il primo picco in corrispondenza del Q2 2020 (arrivo del Covid ed estensione worldwide)
l’assenza di licenziamenti nei 2 anni successivi (con tanto overhiring da parte delle Big Tech)
una crescita dei licenziamenti da Q1 2022 a Q1 2023 (quando per larga parte la GenAI era ancora relegata ad argomento di nicchia)
un assestamento su un livello intermedio negli ultimi quarter
Molto difficile arrivare a conclusioni con i dati disponibili, ma sicuramente i layoff tech di H1 2024 sono molto minori di H1 2023.
Ed in generale, prendere un fenomeno complesso (come i layoff), impattato da una miriade di fattori, e provare a fare un’analisi in funzione di una singola variabile (l’introduzione della GenAI), è metodologicamente sbagliato e porta a tutta una serie di paradossi, come quello di Simpson: la porta d’ingresso principale per analisi semplici, intuitive e sbagliate6.
Semmai stanno facendo scalpore le relocation di interi team tech, dagli Stati Uniti a nazioni a basso costo come India e Messico. Ma è tutta un’altra storia.
7. La GenAI offre un aumento facilmente misurabile della produttività nel Tech?
Partiamo da una considerazione che sembra ovvia ma non lo è: per misurare qualcosa, dobbiamo prima dargli una definizione chiara, esplicita e indiscutibile.
Qual è la definizione di produttività nel mondo dello sviluppo software? Guardiamo 17 aziende tech fino al midollo:
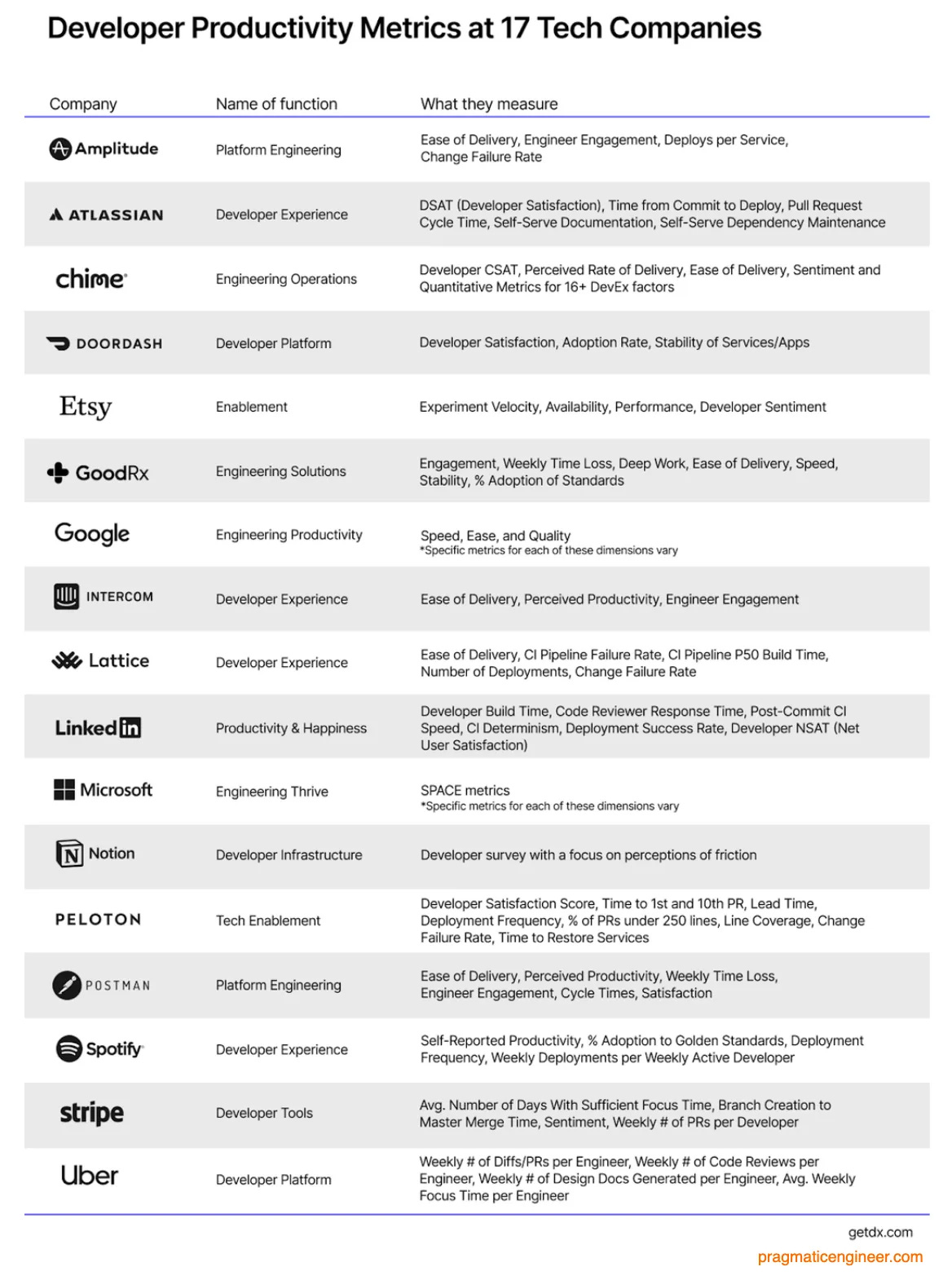
Non ci sono 2 aziende che abbiano la stessa definizione! Eppure in un insieme di cardinalità 17 ci sono 136 coppie7… nessuna di queste coppie è perfettamente identica.
E figuriamoci se andiamo a vedere le aziende che usano la tecnologia, più che essere creatori di tecnologia, dove lo sviluppo software è una parte ma non il core del business!
In realtà, ci sono però un po’ di aspetti comuni. Molte aziende tech si basano su DSAT, Developer CSAT, Developer Survey, Developer Satisfaction Score: è tutto sostanzialmente lo stesso, una valutazione qualitativa da parte degli sviluppatori. Altri si basano su aspetti di successo nei deploy (Change Failure Rate, Deployment Success Rate, CI Pipeline Failure Rate) o altre metriche tecniche su alcuni aspetti del Software Development Life Cycle.
In generale, è un contesto molto frammentato: ci sono alcuni aspetti che sono ampiamente condivisi (misurare la soddisfazione degli sviluppatori), altri completamente respinti (misurare le LOC8 in tutte le loro sfaccettature), tutto il resto è un’area grigia.
L’aspetto fondamentale è la finalità della misurazione della produttività del codice. E bisogna tenere a mente la sempre validissima legge di Goodhart:
Quando un indicatore diventa un obiettivo, cessa di essere un buon indicatore
E chi ha scritto codice sa che molti indicatori sono facilmente hackerabili (a cominciare delle banali LOC, per proseguire con i più complessi), quindi il tema è tutt’altro che scontato.
8. Chi può stare al sicuro è chi si occupa di lavori dove l’empatia è fondamentale?
Se è abbastanza diffusa l’idea che l’impatto della GenAI sui lavori del mondo tech sia alta (anche se abbiamo visto che è tutto da verificare), altrettanto comune è la sensazione che l’empatia umana sia in qualche modo insostituibile.
In realtà… sono davvero tanti gli studi che sostengono la tesi opposta.
Prendiamo il mondo dei medici e di come si relazionano ai pazienti, sia in termini di qualità delle diagnosi che di empatia.
Lo studio più noto è forse Comparing Physician and Artificial Intelligence Chatbot Responses to Patient Questions Posted to a Public Social Media Forum, da cui riporto questo grafico auto-esplicativo:
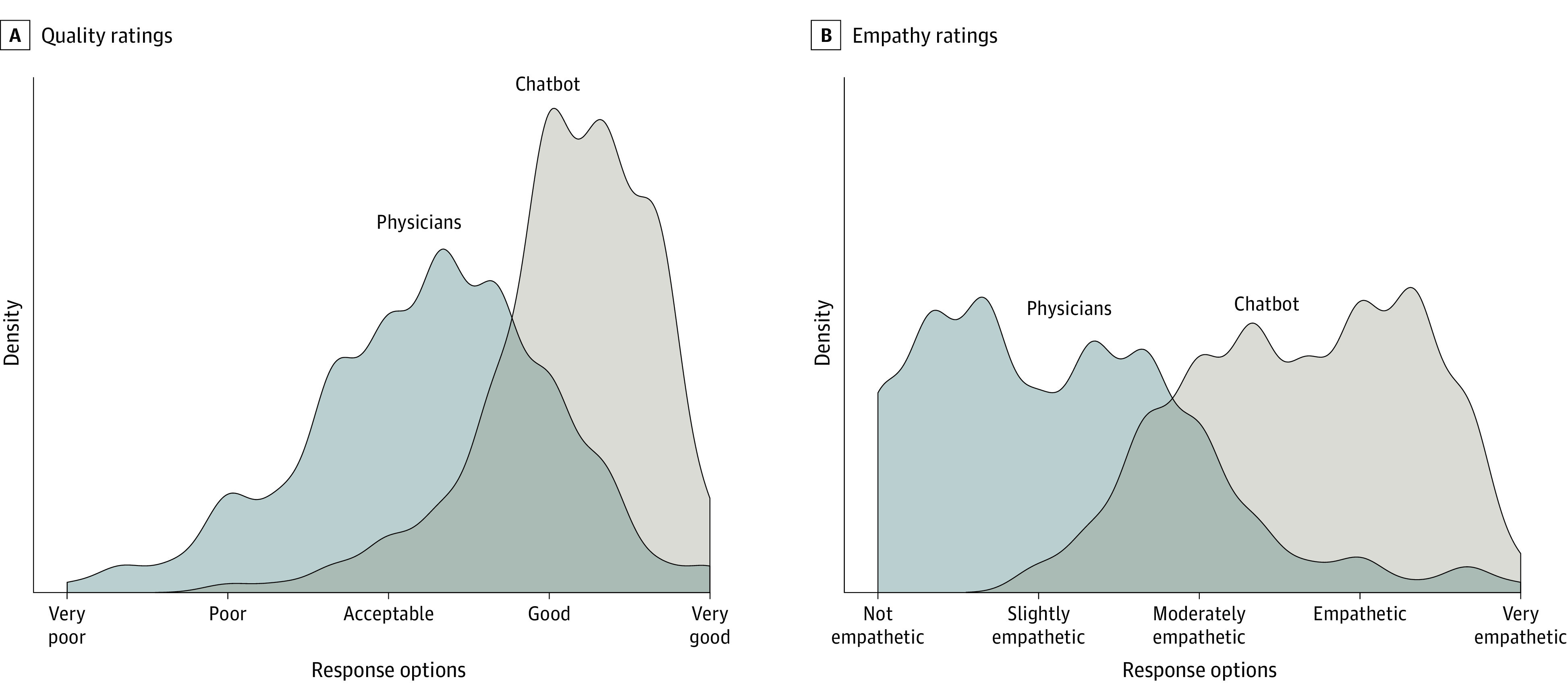
Da notare che il nutrito gruppo di autori è per metà di provenienza tech (reputabili università e aziende), per metà di provenienza health care e life science.
Altri studi più recenti, come quello di Google dal titolo Towards Conversational Diagnostic AI oppure quello dell’EPFL Are Large Language Models More Empathetic than Humans? arrivano a risultati molto simili.
Conclusioni
Congratulazioni se sei arrivato fino a qui! L’articolo di oggi è stato più lungo del solito, ma mi sono sentito in dovere di scriverlo, per cercare di ridurre il gap tra chi sviluppa l’AI e chi la vuole usare con successo.
E tra l’altro mi sento di ringraziare chi nell’ultimo paio di mesi mi ha dato l’opportunità di parlare di queste tematiche, in eventi pubblici e privati, sempre in equilibrio tra approccio tecnico e manageriale: mi fa piacere discutere di queste tematiche con nuove platee, partendo dai fatti (come oggi) e aggiungendo un po’ di opinioni informate!
Quando si parla di Generative AI, mi viene spesso da dire:
C’è tanto fumo, ma c’è anche tanto arrosto
E penso che sia fondamentale per chi ha competenza sul tema fare un passo avanti, non chiudersi nella cerchia dei nerd e provare a capire come anche in una nazione che non brilla per investimenti tech si possa davvero mettere a frutto questa tecnologia strabiliante!
A cui ho spesso il piacere di prendere parte, respirando una boccata di aria fresca e tante idee valide!
Naturalmente allestire un cluster non è l’unica alternativa (ad esempio alcuni LLM sono addestrati sui notevoli cluster del CINECA). Non ho evidenze del costo pay-per-use, ma il costo dell’hardware di base è impressionante e la sua obsolescenza è velocissima… quindi difficile sperare di fare training su cluster terzi a prezzo di saldo.
Con qualche limite di utilizzo.
Derogando dal mio approccio odierno di fornire solo fatti, auguro il meglio agli autori di LLM nativi italiani. Addestrare un modello da zero è un po’ come giocare la Champions League nel calcio… non è facile fare bella figura se dall’altra parte ci sono i migliori al mondo. Mostare benchmark oggettivi è per me un modo per restare ancorati alla realtà e favorire il miglioramento, per provare ad essere realmente competitivi e non solo a parole.
“For every complex problem there is an answer that is clear, simple and wrong.” (H. L. Mencken).
Ripasso di calcolo combinatorio.
Lines of Code.
Grande e prezioso articolo.
Hai riassunto in 10 minuti di lettura quel che avrei potuto imparare in un mese di letture personali integrando le varie fonti.
...e mi hai riportato alla memoria il mago do Nascimento che avevo rimosso dai miei ricordi. :-)
Continua così, sei una figura di riferimento per tanti di noi.
Ciao Alberto! Veramente una bella newsletter! Complimenti e grazie!