


Mentire con dati veri - Parte 1: il selection bias su un caso reale (e come difendersi)
Un "bigino" per orientarsi nelle analisi data-driven... quelle fatte come si deve, e quelle manipolate

Intro
Chi legge questo blog conosce la mia passione nell’uso dei dati per capire il mondo che ci circonda.
E, come recita l’homepage di Google, “mi sento fortunato”! Non c’è mai stata nella storia dell’umanità una tale abbondanza di dati e di informazioni, alla portata di tutti e facilmente accessibili.
Qualcuno subito penserà al fatto che, al tempo stesso, non è mai stato così facile diffondere notizie tendenziose, parziali, o semplicemente false. Questo è il livello 1 della disinformazione: di fake news si è tanto parlato e non ho intenzione di aggiungere nulla.

Quello che personalmente mi preoccupa sempre più è invece un uso distorto di dati veri. Che sia in malafede o per semplice ignoranza, c’è una moltiplicazione di analisi superficiali sui fenomeni più disparati, in cui i dati sono usati come arma per sostenere - in maniera strumentale - una tesi o un’altra. Per chi vuole onestamente districarsi nel mondo attuale, questo livello 2 della disinformazione è quasi peggio delle banali fake news.
Il rischio infatti è che molti finiscano col pensare che “ai dati si può far dire quello che si vuole”. Concludendo quindi, tutto sommato, che un approccio data-driven serva a poco.
In realtà, la frase sopra è vera solo in parte. Penso sia più corretto dire così:
Ai dati si può fare dire quello che si vuole, ma chi ha una competenza reale su distorsioni, bias e “trucchetti” statistici di varia natura può facilmente rendersi conto di quando qualcuno sta barando.
Per questo ho pensato di riassumere, a partire da alcune notizie recenti, i principali punti a cui fare attenzione quando si legge che “i dati sostengono” questa o quella tesi. Quella di oggi è la prima puntata!
Un esempio pratico
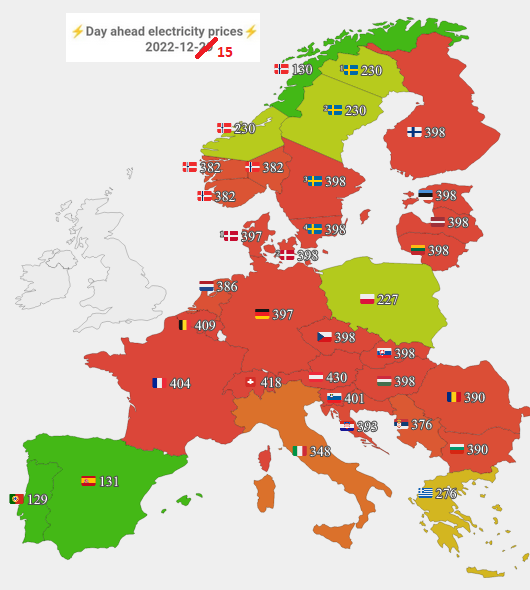
Qualche settimana fa, questa immagine ha avuto una certa diffusione. Parliamo del prezzo dell’energia in Europa.

Non so esattamente chi per primo abbia preso questo screenshot (vero!) dal sito euenergy.live. Quello che ricordo bene sono le considerazioni successive:
“L’Italia paga l’energia 15 volte la Germania”
“Sfruttiamo poco l’energia eolica / solare”
“Se avessimo il nucleare…!”
“È un caso che l’Italia e la Grecia siano le uniche penalizzate, a vantaggio della Germania?”
E via così.
Pochi si sono presi la briga di controllare la veridicità dei dati, ma effettivamente i dati sono reali, come facilmente verificabile.
Il problema è un altro: è stato fatto un cherrypicking indecente! In altri termini, è stato selezionato un campione ad hoc (in questo caso un solo giorno) per sostenere una tesi.
Per i curiosi, i dati di due settimane prima raccontano una storia completamente diversa.
Cosa è successo?
Siamo caduti in un caso banalissimo di selection (o sampling) bias.
Nonostante la semplicità dell’esempio, tanti osservatori (slegati dall’autore del messaggio originario) sono “cascati” in questo semplice trucco, magari perché condividevano alcune delle tesi rafforzate da questi dati. Questa è la principale difficoltà in un approccio data-driven: non bisogna partire mai dalle proprie idee, ma sempre dai dati.
Nel caso di esempio, a mio avviso l’errore è stato deliberato: di fatto, anziché seguire un approccio data-driven reale, si è semplicemente cercato qualche dato utile a sostenere alcune convinzioni… e chi cerca, trova.

In realtà il problema della scelta dei dati può concretizzarsi anche in maniera del tutto involontaria e talvolta inevitabile.
Questa è una vignetta geniale che spiega il problema di tutti i sondaggi: la popolazione si divide in due (chi risponde ai sondaggi, e chi no) e notoriamente la prima categoria non è rappresentativa dell’intera popolazione!

In realtà possiamo trovare tanti esempi molto più sottili.
Un grande classico sono gli articoli sulle caratteristiche comuni a una qualche elite: atleti vincenti, imprenditori di successo e cose del genere. L’approccio standard è trovare un set di caratteristiche che li accomuna (diciamo un MCD). E a prima vista sembra perfettamente logico!
La realtà è un’altra. Un approccio robusto non può fare a meno di un campione eterogeneo: ad esempio, bisognerebbe prendere un gruppo di imprenditori che hanno avuto successo1 e altrettanti che non lo hanno raggiunto. Solo in questo modo, avendo una completa rappresentazione delle due classi (successo sì / no), possiamo andare a studiare le variabili realmente discriminanti tra i due gruppi! E magari si scoprirà che alcune caratteristiche del gruppo di successo sono in realtà presenti anche nell’altro, e quindi poco significative2.
Come superare il bias
Tornando al caso in cui ci si trova di fronte ad un’analisi effettuata da altri, che sia un articolo di giornale o un post sui social, già rendersi conto della possibile esistenza di un problema di selection bias è un primo passo: non possiamo fare a meno di chiederci se i dati sono reali (1) e se sono stati scelti ad hoc (2).
Per andare oltre, è fondamentale l’accesso al dato grezzo. E le strade sono principalmente due:
La disponibilità di open data e, se possibile, di analisi open source;
La possibilità di effettuare uno scraping dei dati.
Nel primo caso, i dati utilizzabili sono scaricabili in un formato accessibile, per permettere a chiunque di effettuare analisi successive; e magari, l’analisi è effettuata con un linguaggio come Python o R ed il codice sorgente è liberamente disponibile. In questa casistica, qualcuno ricorderà qualche mia analisi del 2020 sul Covid, alcune in Python e altre in R.
Questo è il caso ideale: l’analisi è riproducibile dalla testa ai piedi, ed eventuali errori metodologici o distorsioni possono essere facilmente verificati.
Purtroppo il tema dei dati e delle analisi open non è particolarmente sentito. Rimane l’alternativa numero due, ossia lo scraping, che permette di simulare la navigazione manuale di tante pagine web e il successivo scaricamento in tabella di alcuni dei dati.
Nel caso di prima, si tratta di:
Simulare il cambio della data di riferimento dei prezzi dell’energia (box in blu)
Scaricare e mettere in tabella (diciamo, in un dataframe) i prezzi in sé (box in arancione)

Mi sono trovato molto bene con Scrapy, l’ideale in un caso semplice come quello sopra, ma ci sono tante alternative, a cominciare da Selenium.
E così, se vogliamo farci un’idea reale dei prezzi dell’energia su un mese intero (anziché su un giorno scelto ad hoc), possiamo ricostruirci questo grafico:
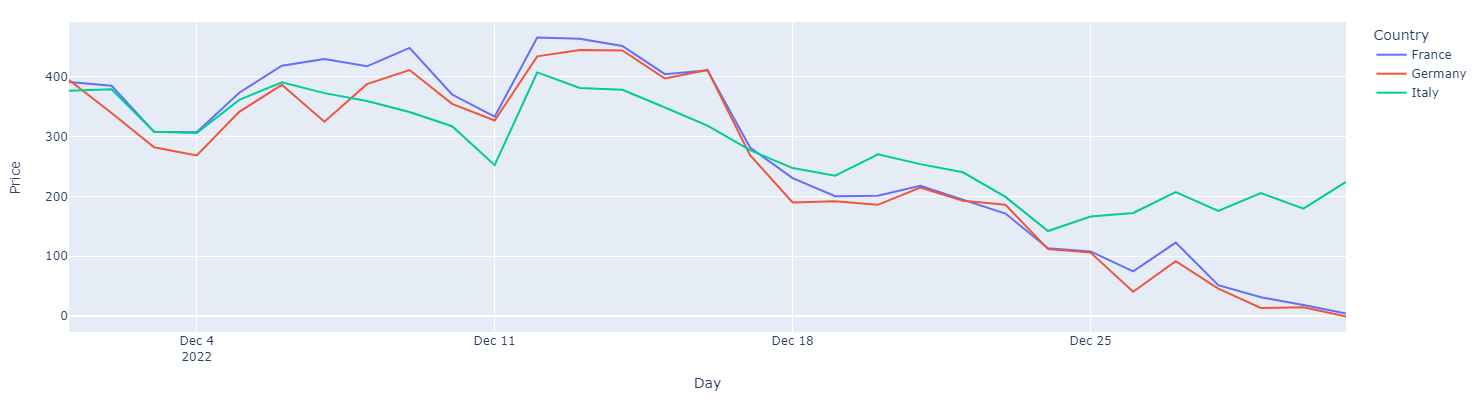
È lampante che a questi dati si può far raccontare qualsiasi storia: basta scegliere il giorno adatto! Il punto è che non dovrebbe essere difficile rendersi conto che un singolo data point non può essere una base di analisi ragionevole.
Di contro, raccogliere i dati su un mese o un anno permette almeno di farsi un’idea più completa.
Conclusioni
Quello che ho presentato oggi è uno dei più classici bias statistici. Piace a tutti - a me per primo! - saltare alle conclusioni, ai ragionamenti e alle discussioni… ma anche un occhio attento può facilmente sottovalutare alcuni errori (deliberati o meno) nella raccolta e presentazione dei dati.
Purtroppo non c’è una soluzione facile.
Verificare autonomamente i dati e l’analisi, come ho fatto in questo caso, richiede un po’ di tempo, la capacità tecnica di scrivere codice… e la voglia di farlo! La combinazione delle tre cose è molto rara.
Rimane l’autorevolezza dell’autore/autrice e la sua onestà intellettuale, che è a mio avviso un ottimo punto di partenza. Ma chiunque può fare errori e penso sia fondamentale, su tematiche di interesse pubblico, una politica di:
Dati aperti, con fonti riportate chiaramente e liberamente consultabili
Analisi aperte, in linguaggi di programmazione open
Diffusione della competenza, per permettere a più persone di essere autonome nelle verifiche
Vedremo prossimamente altri casi e altre fattispecie di bias. Con questo articolo, abbiamo giusto scalfito la punta dell’iceberg!
Quale che sia la definizione di “successo”.
Di fatto ho descritto il requisito alle base di qualsiasi modello di classificazione binaria. Gli algoritmi di machine learning supervisionato richiedono un’adeguata presenza della classe positiva e di quella negativa.
Complimenti! Io stessa quando analizzo dati di traffico per valutare le performance digitali dei clienti mi troppo a voler dedicarci più tempo interrogandomi se sto traendo conclusioni ‘infettate’ da un bias. Non è semplice, spesso in fase di presentazione dei risultati cerco un ulteriore confronto sulla conclusione anche assieme al cliente che potrebbe avere una sua visione data da dati a cui non ho accesso.